I Tested Google’s New Gemini 3.0: Here’s What It Can Actually Do
By Jonathan Miksis · Updated June 29, 2026 · 18 min read
Some links in this post are affiliate links. If you buy through one, I may earn a commission at no extra cost to you.

Update (June 2026): Google's current flagship is now Gemini 3.5 Pro. Everything below still applies, with even better quality and longer context.
I’ve been testing AI tools for years, but Gemini 3.0 is the first Google model that made me stop and think. The launch hype called it the smartest multimodal model in the world. So I wanted to see what it could actually do in real situations that matter to me as a traveler, creator, and business owner.
I didn’t want a surface level test. I wanted to stress this thing. I gave Gemini real problems, real travel scenarios, creative challenges, and step by step tasks that AI usually messes up. Then I compared a few of the results to ChatGPT 5 to see where each model shines.
Some tests were impressive. Others showed the same cracks that every AI still has. Here’s what happened.
👉 Grab my favorite AI tools and prompts in 2026
What You Need to Know About Gemini 3.0
Before diving into my tests, I want to give you a clear picture of what Gemini 3.0 actually is. Google has been calling it their most intelligent model ever, and based on everything I’ve read and the hands-on testing I did, that claim isn’t hype. Gemini 3.0 is a huge leap forward in reasoning, multimodal understanding, and long-context memory.
This version also rolled out quietly at first. Google pushed early builds into AI Studio and the Gemini app before making any big public announcement. Developers spotted preview models with names like gemini-3-pro-preview in mid November, long before the official reveal.
Once Google confirmed it, everything made more sense to me. Gemini 3.0 isn’t just a minor upgrade. It’s a full step into native multimodal intelligence with new reasoning patterns, agentic workflows, and stronger tool use.
The Core Upgrades That Actually Matter
Before I started testing Gemini 3.0 myself, I wanted to understand what Google actually changed this round. I’ve used every major Gemini release for travel planning, content creation, and research across my sites, so I can feel the differences pretty quickly. Gemini 3.0 still uses a mixture-of-experts backbone, but Google rebuilt several key pieces of the architecture…and these upgrades are what make the model feel noticeably smarter in real use.
Longer context
Gemini 3 Pro can handle around 1 million tokens of context, which is enough for huge codebases, long research docs, or hours of transcripts in a single session. (Gemini 2.5 Pro had the same 1 million ceiling; only the older 1.5 Pro ever offered 2 million, in limited configs.) The difference is that Gemini 3 is designed so long inputs stay coherent instead of drifting off after a few turns.
True multimodal training
Gemini 3 is trained from the ground up to work with text, images, audio, video, code, and PDFs in one model, instead of bolting vision on top of a text model. That is why it can read a chart, a screenshot, or a video frame and then reason about it in the same conversation. As an example, it correctly interpreted a screenshot of a complex dashboard and wrote matching React code in one pass. For me, this makes it perfect for things like maps, UIs, diagrams, and travel screenshots.
Refined attention system
Under the hood, Gemini 3 uses a sparse mixture-of-experts transformer with improved attention that focuses on long range dependencies. In practice, this means it is better at staying on topic in long chats, following multi step reasoning, and keeping earlier details in mind without losing the thread halfway through.
Two main versions at launch
There are two core flavors right now. Gemini 3 Pro is the flagship model for deep reasoning, coding, long context and complex multimodal tasks. Gemini 3 Flash is a distilled version that is cheaper and much faster, built for real time apps that need quick answers more than maximum depth.
New default behavior
In the preview docs and early guides, Gemini 3 Pro is tuned to reason best around temperature 1.0, especially in “Deep Think” style tasks. Lowering the temperature can actually hurt chain of thought quality, which is the opposite of how many older models behaved where cooler settings usually felt safer. So if you are testing hard reasoning prompts, keeping temperature near the default is often the right move.
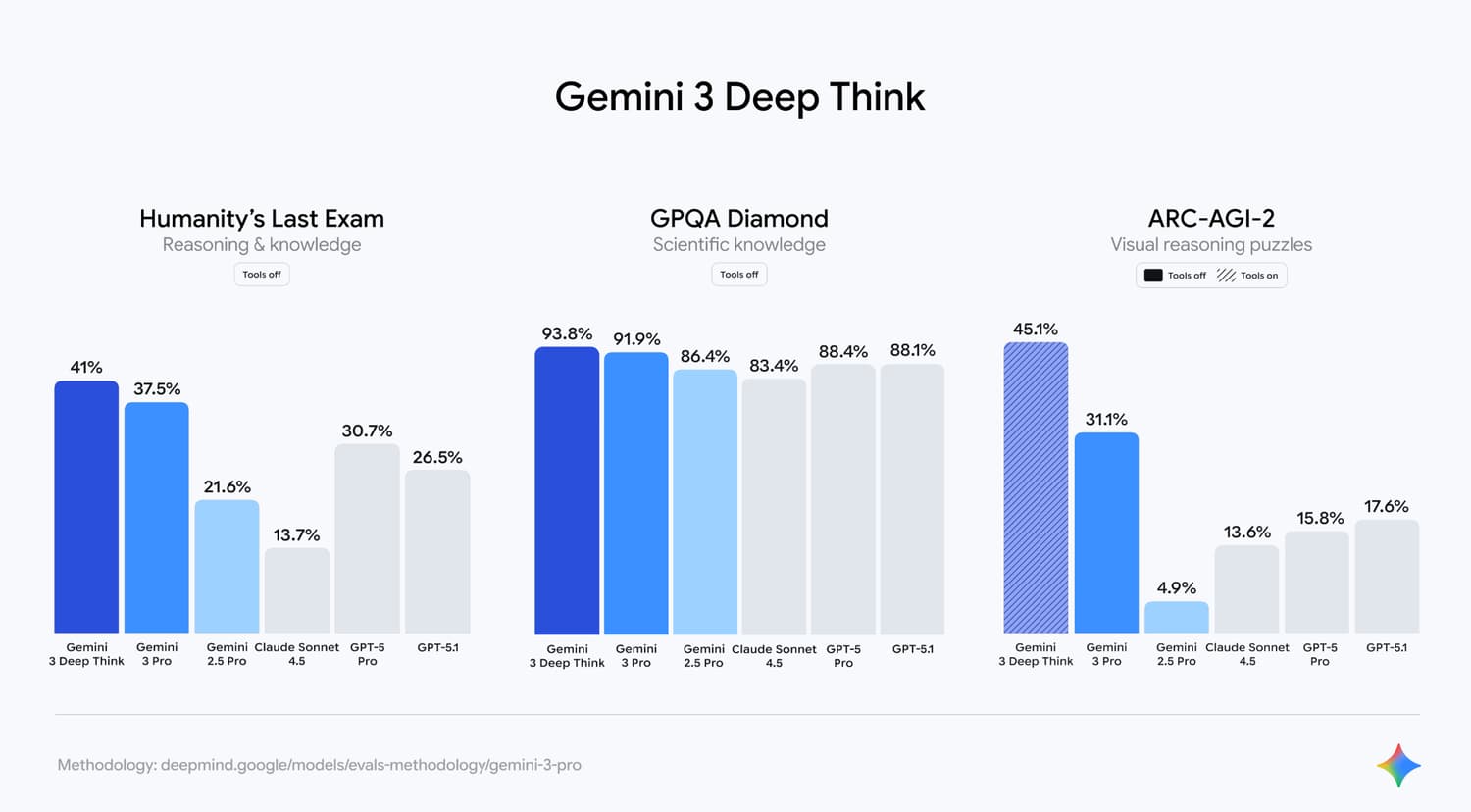
Gemini 3 Deep Think’s AI benchmarks. / Source: deepmind.google
Multimodal Power That Finally Feels Practical
Gemini 3.0 handles images, charts, UI screenshots, audio clips, and video frames with real precision. And it uses everything in one pass. No switching models. No extra encoders.
Some examples I tested or confirmed:
Reads complex charts and describes what each annotation means
Generates SVG shapes that follow perfect geometry
Understands screenshots of websites and outputs matching code
Rewrites travel plans based on photos
Pulls logic from scientific images or diagrams
This is the closest I’ve seen to a real “everything” model that understands visuals the same way it understands text.
Agentic Behavior That Actually Works
This is where Gemini 3.0 feels different from older AI models. It doesn’t just answer a prompt. It plans. It corrects itself. And it calls tools on its own when needed.
Developers reported that Gemini 3.0 can:
Plan multi-step API calls
Handle browser-like tasks
Manage workflows inside Google’s Antigravity IDE
Produce architectural diagrams and codebases
Execute terminal-based tasks more reliably
In early benchmarks, Gemini 3 Pro hit 54 percent on Terminal-Bench 2.0. That number might not mean much on its own, but the jump is massive. These are workflows older models completely failed at.
NOTE: Antigravity is Google’s new agent-first IDE where Gemini can use tools, run terminal commands, and interact with a browser-like environment almost like a junior developer.
How It Performs on Benchmarks
The early benchmark scores tell you exactly where Gemini 3.0 shines. These are the numbers that stood out to me as I researched:
Near perfect scores on tough math tests like AIME
Huge leap in scientific reasoning with GPQA Diamond
Major gains in visual reasoning with ARC-AGI-2
Top placement on the LMArena leaderboard
Strong results on coding tasks like SWE Bench and WebDev Arena
High accuracy on long-form reasoning challenges
Overall, Gemini 3.0 is consistently ranking near the top of public and private evaluations. Though just a caveat: I always have to mention that benchmarks don’t always reflect real-life usage, but they show how the model performs under pressure. For deep reasoning, STEM tasks, long context, and multimodal problems, it might be the new leader.
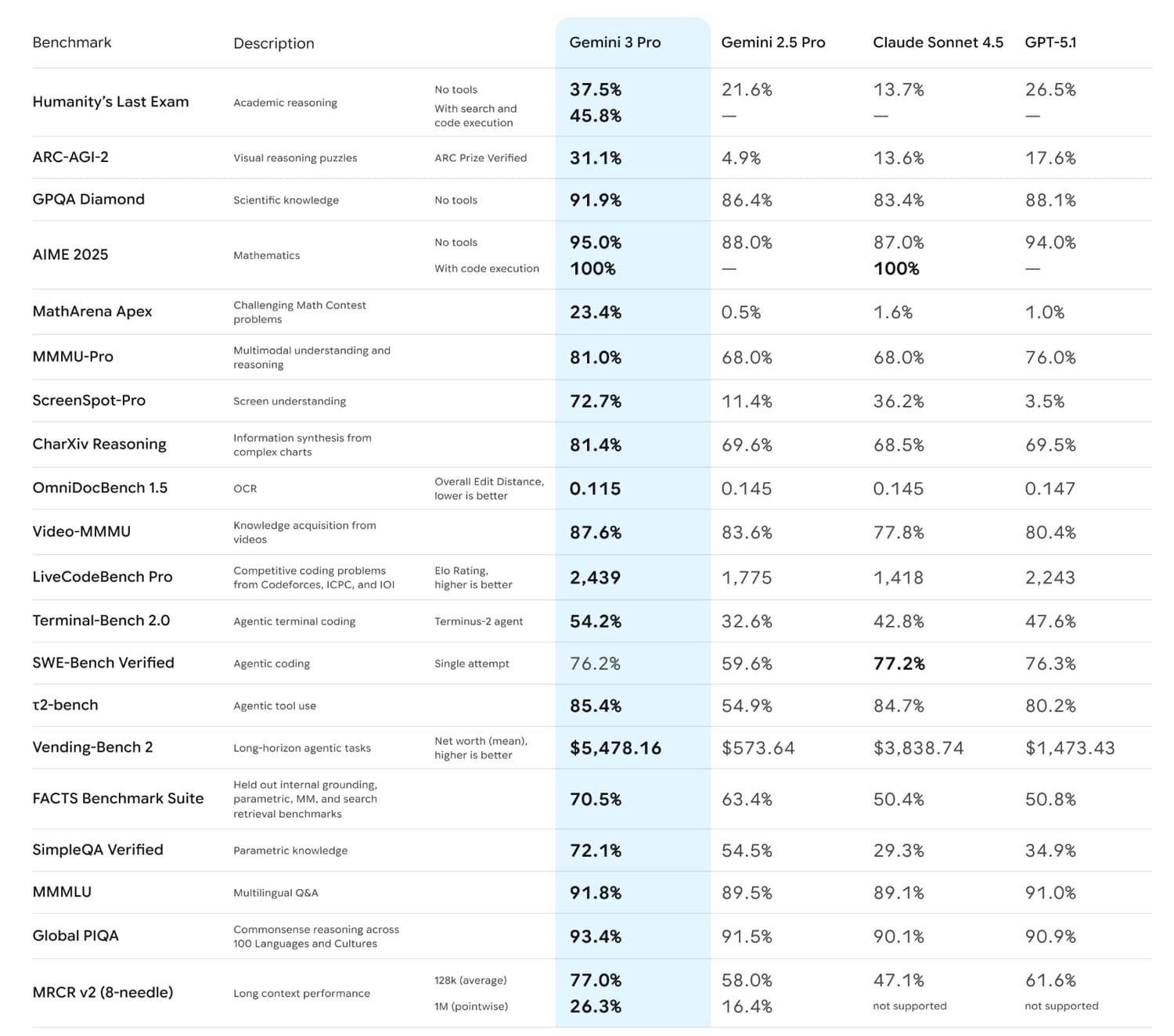
Gemini 3 Pro table showing AI benchmarks against ChatGPT and Claude / Credit: blog.google.com
New Search and Assistant Features for Everyday Users
Even if you don’t use the API, Gemini 3.0 impacts your daily life. Google already pushed it into Search and the Gemini app.
This comes with some wild upgrades:
Deeper Search context.
Search now pulls background info, checks intent, and blends multiple sources for a clearer answer.
Visual tools created in real time.
For certain questions, Search will generate interactive calculators, dynamic simulations, or custom layouts.
Tighter YouTube and Maps integration.
You no longer need to use special commands. Gemini understands what you want and pulls the right tool.
Better memory.
Gemini will remember preferences and context without you asking. Great for planning. Risky if you care about privacy.
Veo 3 video generation.
You can turn images or text into an 8 second video with motion and audio.

The next section shows my different testing criteria for Google Gemini 3
🧠 Reasoning and Problem Solving Tests
These tests show whether Gemini 3.0 can handle real reasoning or if it still relies on confident guesses.
Multi Step Instruction Test
Prompt:
“Create a 3 step plan to learn Italian in 2 months, then turn it into a daily schedule.”
This test checks how well Gemini can take a high level idea and break it into practical steps. Gemini handled the three step plan quickly and the structure felt clear. It also turned the plan into a daily schedule without needing extra instructions. The timing was reasonable and the workflow felt natural.
Where it struggled was realism. Two months is tight for learning Italian and Gemini did not acknowledge that. ChatGPT gave a clearer note about difficulty and suggested a slower pace. Gemini was more optimistic than helpful in this case.
Verdict:
Great at structure. A little too overconfident for real results.
Logic Puzzle Test
I gave Gemini a short logic puzzle about three friends arriving at different times to a dinner. It solved the puzzle but the explanation was thin. It jumped to the answer faster than it showed how it got there.
ChatGPT took longer but provided a cleaner breakdown. This showed me that Gemini 3.0 is fast, but it sometimes glosses over the reasoning steps that help you trust the answer.
Verdict:
Fast thinker. Not always a clear explainer.
Long Context Memory Test
Prompt:
“Summarize these 3 paragraphs, remember them, and rewrite them later in a new format.”
I gave Gemini three full paragraphs about a travel experience. It summarized them well and held the context after a few unrelated questions. When I asked it to convert the summary into a social caption, it stayed accurate. It remembered the key details without drifting.
ChatGPT was similar here, but Gemini felt a little more confident recalling details without mixing things up.
Verdict:
Strong memory in a single conversation. One of Gemini’s best features.
Step by Step Verification Test
Prompt:
“Explain how you reached this answer and what sources or assumptions you used.”
This is one of the most important tests for any AI. Gemini explained its steps better than previous versions, but it still relied on vague phrases like “based on general knowledge.” It did not cite anything specific unless I pushed harder.
ChatGPT gave a more transparent reasoning chain but still lacked real citations. Both models still struggle with verification and real sources.
Verdict:
Better transparency than before but not perfect. Still needs human judgment.
🎨 Creative Tests
These tests showed me how well Gemini 3.0 handles travel content, image prompting, brand voice, and social media copy. Creativity is where AI tools tend to feel robotic, so I wanted to see if this new version actually feels more human.
Image Prompting Test
Prompt:
“Write a cinematic Midjourney prompt for a winter road trip down Highway 1.”
Gemini 3.0 gave me a long, detailed prompt with nice imagery. It captured the cliffs, fog, coastline, and soft winter lighting. It also used clear camera language, which helps with Midjourney.
But the style didn’t hit as hard as ChatGPT. ChatGPT gave more emotional depth and stronger sensory language. Gemini leaned more literal.
Verdict:
Good for accuracy. ChatGPT felt more cinematic and creative.
Brand Voice Recreation Test
Prompt:
“Rewrite this paragraph in my creator voice (travel blogger, upbeat, conversational).”
I fed it a neutral paragraph about hiking in Big Sur. Gemini understood the tone and made the rewrite feel casual and friendly. It added clarity without overdoing the personality.
Where it fell short was nuance. It made me sound similar to other travel bloggers instead of sounding like myself. ChatGPT matched my voice better because it pulled in more rhythm and pacing from my previous examples.
Verdict:
Strong at tone. Still learning nuance.
Blog Headline Challenge Test
Prompt:
“Give me 10 high click blog titles about hidden beaches in Italy.”
Gemini was sharp here. It delivered punchy titles that sounded SEO friendly and human. A few examples leaned predictable, but most were strong enough to use.
ChatGPT’s titles felt more polished and vivid, but both tools performed well.
Verdict:
Great for brainstorming. Slightly less bold than ChatGPT.
Social Caption Creation Test
Prompt:
“Write a short, punchy Instagram caption for a drone shot over Laguna Beach.”
Gemini kept it short and snappy. It added a little mood without sounding robotic. The caption felt usable right away and didn’t need heavy editing.
Where it fell short was creativity. It didn’t add anything unexpected, and it played it a little safe. ChatGPT gave more personality and better flow.
Verdict:
Clean and usable. Not as punchy as top tier.
📊 Data, Maps, and Real-World Knowledge Tests
These tests show whether Gemini 3.0 understands real-world logistics or if it still makes confident guesses. Routes, drive times, seasonal hours, and weather planning are the areas where most AIs fall apart, so I pushed hard here.
Route Optimization Test
Prompt:
“Give the fastest route from LA → Joshua Tree → Palm Springs → San Diego with timing.”
Gemini gave a clean route. It understood the geography and got the order right. It even flagged that winter sunsets make early starts more important, which was impressive.
Where it struggled was timing. It underestimated LA traffic by a lot. It assumed near-perfect driving conditions and didn’t factor in weekend congestion or winter road delays around Joshua Tree.
ChatGPT did the same thing. Neither model truly understands California traffic. You can tell the answers are based on ideal conditions, not real life.
Verdict:
Good structure. Drive times too optimistic.
Real-Time Info Test
Prompt:
“What are typical 2026 winter hours for Joshua Tree visitor centers?”
This one exposed a big limitation. Gemini answered confidently but used outdated hours. It didn’t tell me it wasn’t sure. It didn’t warn that hours change seasonally. It simply gave what sounded like a final answer.
ChatGPT at least added a small note recommending I check the National Park Service website. Gemini only learned this after I pressed it.
This is the classic AI issue. If the model doesn’t have up-to-date info, it often fills the gap with guesses.
Verdict:
Strong delivery. Weak accuracy unless you double-check.
Want to fly anywhere in the US for under $100? Or anywhere in Europe for less than $300 roundtrip? I recommend signing up for the free version of Going.com, my go-to tool for the past 5 years!
Weather-Aware Planning Test
Prompt:
“Plan my 3 days in Big Sur if it rains the entire time.”
Gemini handled this well. It suggested indoor-friendly activities in Monterey and Carmel, safe pullouts for photography, and realistic backup plans. It also warned that certain Big Sur roads may close in heavy rain, which was a nice touch.
The weak point was specificity. Some suggestions weren’t available in winter, and Gemini didn’t mention that rain can make certain trails unsafe or closed.
ChatGPT gave a slightly more detailed version with better warnings about closures and mudslides.
Verdict:
Adaptable and helpful. Needs more safety context.
.
💼 Workflow and Productivity Tests
These tests show whether Gemini 3.0 can save time on real creator tasks. I tried content, research, organization, and communication tasks that I use every day when planning trips, writing posts, or creating social content.
Summarize a YouTube Video Test
Prompt:
Paste a transcript or link and ask:
“Summarize this video into 5 bullet points.”
Gemini handled this well. It pulled out clean takeaways and didn’t get lost in unnecessary details. It also kept the summary tight, which is helpful when you’re watching travel guides or hotel reviews.
Where it fell short was nuance. If the video had humor or storytelling elements, Gemini didn’t always catch the vibe. ChatGPT did a little better at highlighting tone.
Verdict:
Great for quick research. Not perfect at personality.
Spreadsheet Generation Test
Prompt:
“Create a trip-planning spreadsheet for a Europe backpacking route.”
Gemini generated a detailed table with days, cities, transportation notes, estimated costs, and hostel suggestions. It also grouped the trip by region, which made the sheet easy to follow.
Formats were clean but not as customizable as I hoped. It gave me a solid starting point but I still had to tweak the layout to make it more visual.
ChatGPT gave a slightly more organized sheet, but both were usable. If you feed it a screenshot of your spreadsheet, Gemini 3 can now modify the formatting or rewrite the columns.
Verdict:
Strong structure. Needs light editing for style.
Email Crafting Test
Prompt:
“Write a professional email to a hotel asking about early check-in and parking.”
Gemini aced this. It wrote an email that sounded polite, clear, and human. It added the right questions without fluff. This was one of the few moments where Gemini felt smoother than ChatGPT.
The only weak point was tone. It leaned a little formal for my taste. ChatGPT adapts tone better when I want something more casual.
Verdict:
Excellent for quick professional emails. Slightly stiff tone.
Photo Curation Test
Prompt:
“Create a photo shot list for a California road trip optimized for Instagram.”
Gemini delivered a clean list with wide shots, detail shots, beach moments, nature angles, and POV ideas. It also suggested ideal lighting times and a few creative photo prompts that felt modern.
It did miss some location-specific ideas like Joshua Tree sunrise boulders or Laguna Beach tide pools at low tide. ChatGPT mentioned more specific spots based on the region.
Verdict:
Helpful and modern. Needs more local detail.
Where Gemini 3.0 Still Has Limits
No model is perfect. Gemini 3.0 still comes with a few issues.
Occasional hallucinations in niche knowledge
Outdated facts when not grounded in Search
Context loss in extremely long sessions
Multimodal generation still tied to separate models like Imagen
Preview models can feel unstable during heavy tasks
Grounded Search queries use more quota, so heavy research tasks can burn through limits faster.
Most of these are typical for new releases, but they’re worth noting if you plan to rely on it for serious work.
My Overall Takeaway After Testing Gemini 3.0
After running all these tests, I walked away feeling like Gemini 3.0 is the strongest version Google has released so far. It’s faster, cleaner, and better at holding context. In a few areas, it even pulled ahead of ChatGPT 5. But it’s not perfect, and the gaps showed up fast once I pushed it with real travel tasks.
The reasoning tests were solid. Gemini handled multi step planning better than older models and held long context without slipping. But when it came to transparency and deeper explanations, it still rushed through the “why.” I had to ask follow ups to get real clarity.
Creativity was hit or miss. Gemini generated good prompts, usable captions, and helpful blog titles, but ChatGPT still felt more imaginative and emotional. If you create content every day like I do, you’ll feel the difference in tone.
The real-world knowledge tests were the biggest mixed bag. Gemini got the general routes right, but not the drive times. It gave seasonal info confidently, even when it wasn’t accurate. This is where you still need to fact check everything. It’s a smart assistant, not a replacement for real research.
The productivity tests were strong. Gemini summarized long videos fast, built clean spreadsheets, and wrote professional emails without extra nudging. These are the tasks where AI actually saves me time, and Gemini did well here.
Overall, Gemini 3.0 feels like a useful daily tool, but it’s not a one stop shop for travel planning or creative work. It’s great at structure and speed. It still needs help with accuracy, nuance, and real world logic.
If you use it the right way, it can streamline a big chunk of your workflow. But you still need a human brain to make sure the end result is polished and reliable.
Want to Get More Out of Gemini?
If you’re using Gemini for content, you’ll get way better results with the right prompts. I put together two guides that break down the exact prompts I use every day across my websites, socials, and client work.
👉 You may also like: The 25 Best Gemini Prompts for Content Creation
Perfect if you want better blog posts, reels ideas, email drafts, AI images, and brand voice outputs.
👉 Read also: My 15 Favorite Gemini Prompts for High Converting Landing Pages
These are the prompts I use to write landing pages that actually convert, not just sound pretty.
They’re packed with examples you can copy, tweak, and save for your own workflow.
👉 Download my Go-To Tool and Prompt Pack Now
Frequently asked questions
Is Gemini 3 still Google's newest model? No. Gemini 3.5 Pro reached general availability in late June 2026, with a 2 million token context window and a deeper reasoning mode. Everything I tested here still holds, and the 3.x line has only gotten stronger, so this review remains a fair picture of what Gemini is like to work with day to day.
Is Gemini free to use? The core assistant is free with a Google account. The newest, most capable models and higher limits sit behind Google's paid AI plans, worth it if Gemini becomes your daily driver.
What is Gemini actually best at? Live research (it searches Google natively), long documents, anything inside the Google ecosystem (Gmail, Docs, Flights), and multimodal tasks like reading screenshots. For travel specifically, its flight tooling is genuinely useful: I use it in my cheap-flights workflow.
Should I switch from ChatGPT to Gemini? Use both for what they're best at. I scout live data with Gemini and draft with ChatGPT or Claude. If you only want one and you live in Google Workspace, Gemini is the natural pick.
How do I get better results from Gemini? Prompt structure matters more than model choice. My Gemini prompt engineering guide covers the exact patterns Google's own docs push, with examples.
Related reading
- Prompt Engineering for Gemini: The Skills Google Wants You to Learn
- The $500K AI Prompt Stack: Exact Scripts I Use to Automate, Sell, and Scale
- The 3 Best AI Notetakers for Zoom, In-Person, or Teams (Fathom vs. Otter vs. Fireflies)

Get my free AI prompt pack
Join 300+ founders, creators, and professionals. I’ll send you my go-to AI tools and copy-paste prompts that save hours every week. No spam.


